
The Challenge: Trusted Data is Still Hard to Access
Many organizations have already invested in modern data platforms — Lakehouses, Warehouses, and enterprise analytics environments that store large volumes of structured, governed information. The infrastructure is there. The challenge is getting to it.
Business stakeholders typically rely on predefined dashboards or submit requests to data teams to answer new questions. That model protects data quality and governance, but it creates bottlenecks as demand for insights grows. A question that should take minutes can take days.
The underlying cause is often the data’s legibility. Databases built to support applications were never designed to be understood outside the teams that built them. Column names like “PK_FormID,” unnormalized records, and missing data dictionaries are common. Early attempts to point generative AI directly at these environments required significant workarounds — flattened views, manually enriched data, and lengthy pre-prompts just to return useful answers. The results were fragile and difficult to maintain. Fabric Data Agents are designed to address this directly.

Conversational Access to Enterprise Data
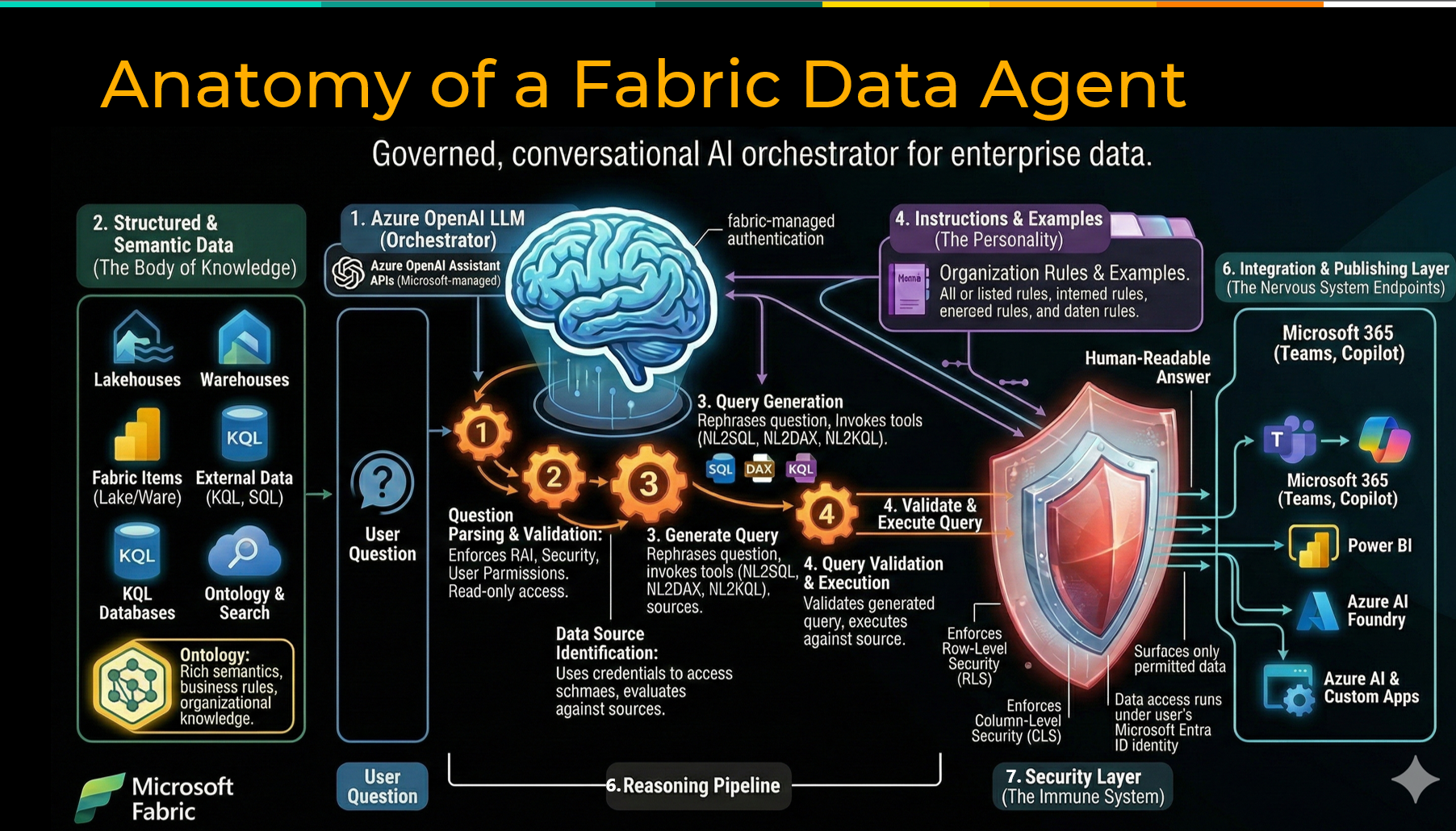
Fabric Data Agents allow users to interact with structured data through natural language. Instead of navigating complex reporting environments or writing SQL, users ask questions in plain language and receive contextual responses derived from governed data sources. Supported sources currently include Warehouse, Lakehouse, Eventhouse (KQL Database), Semantic Model, Ontology, and Azure AI Search for unstructured data.
Behind the scenes, the agent interprets the request and translates it into the appropriate query — SQL, DAX, or KQL — across Fabric assets. Queries run under the user’s own Microsoft Entra ID identity, meaning existing row-level security, column-level security, and workspace access controls remain fully enforced. The result is a more collaborative relationship between business and data teams, where trusted insights can be surfaced quickly without compromising governance.
Interested in how Fabric Data Agents actually work?
We explore the engineering challenges behind connecting AI models to enterprise scale data and how Fabric Data Agents simplify this process in our previous newsletter.

Why Semantic Context Matters
Conversational access to data only works when the AI system understands how the underlying data is structured and how different concepts relate to one another. Without this context, natural language queries can produce ambiguous or inconsistent results.
Fabric IQ serves as the semantic foundation connecting your data, your business definitions, and your AI systems. It introduces two key components relevant to data agents: the Semantic Model, which maps business concepts to technical data elements, and the Ontology, which functions as the enterprise vocabulary layer to define entities, relationships, and business rules in a way that agents can reason over. A question like “which stores are underperforming this quarter” requires the agent to know what “underperforming” means in your business context, which tables hold the relevant data, and how those tables relate to one another. The semantic layer provides that grounding.
For many organizations, building and maintaining strong semantic models has become one of the most important prerequisites for effective AI-enabled data access.
From Reports to Actionable Insights
Traditional analytics environments answer the questions that were anticipated when they were built. When a new question emerges, the process typically starts over — a request to the data team, a new report, more wait time.
Fabric Data Agents introduce a more dynamic model of interaction. In the demo, a single agent session moved from total revenue by store last quarter, to which product categories drive the highest revenue and margin, to which stores are at risk due to low inventory on high-revenue products. Each question built on the last, and the final query returned a definitive result: no stores were currently at or below their reorder point for top-selling products, a confirmation of business health that is just as actionable as identifying a problem would have been.
Emerging questions can be investigated directly against trusted data by the people closest to the business problem, with meaningful downstream effects on decision speed and data literacy across the organization.
Please note this demo does not contain sound.
Preparing the Data Foundation for AI
The quality and reliability of a Fabric Data Agent experience is directly dependent on the state of the data environment underneath it. A clear implementation sequence has emerged from early deployments: establish a strong Semantic Model first, layer an Ontology on top to introduce business context, configure detailed agent instructions that define scope and business rules, then test and tune before enabling broad access.
A few practices have proven particularly important. Narrowing agent scope — fewer data sources, fewer tables, more focused subject matter — meaningfully improves answer consistency. Detailed instructions that specify joins, filters, and business definitions reduce ambiguity. Sample questions with pre-specified queries provide reliable anchors for common requests. And building an evaluation harness before rollout, including stress testing with edge-case questions, is the difference between a pilot and a production-ready deployment. Organizational change enablement matters equally — the technology can be configured correctly and still underdeliver if business users haven’t been set up to use it effectively.
Preparing your data foundation for AI?
Before deploying solutions like Fabric Data Agents, organizations need clarity on governance, data definitions, and high-value use cases.

Expanding the Role of AI in Data Platforms
Fabric Data Agents are one component of a broader shift in how AI systems interact with enterprise data. As agentic capabilities mature, these systems will participate in multi-step workflows, collaborate with other agents, and support complex analytical tasks across an organization’s full data estate.
Microsoft’s use of the Model Context Protocol (MCP) is an early signal of this direction. When a Fabric Data Agent is published, MCP is enabled by default, exposing a standardized endpoint that other AI systems can call. This allows Fabric Data Agents and semantic models to function as a shared, callable data layer within a broader agentic ecosystem, rather than each agent building its own connection to underlying data. The investments made today in semantic models, ontologies, and well-configured agents become reusable infrastructure that future agentic workflows can draw on.
Conclusion
Fabric Data Agents offer a practical path toward making enterprise data legible, accessible, and useful to the people who need it — while preserving the governance controls organizations depend on. The organizations seeing early success share a common approach: they invest in the semantic foundation first, configure agents with clear scope and detailed instructions, validate outputs before broad rollout, and bring their business users along through the process.
As agentic AI capabilities continue to develop, the data foundations being built today will determine how effectively organizations can participate in what comes next. For organizations already in the Microsoft Fabric ecosystem, Fabric Data Agents are one of the more accessible entry points available right now.
Ready to explore how AI-powered data experiences with Microsoft Fabric?
Lantern helps organizations modernize data platforms, establish strong governance, and enable AI-driven insights across the enterprise.
Want to see Microsoft Fabric Data Agents in action?