This post is part 1 of a two-part Modern Data Platform Series examining Microsoft Fabric and Databricks. The question isn’t which platform wins, it’s knowing when each one fits, and how to make them work together.
Every few months, I find myself in a room where the same argument is playing out: an engineering lead who’s invested two years building with Databricks defending that bet to a new CDO who just read a Gartner note about Microsoft Fabric. Or it’s the reverse: a Fabric-first team wondering whether they’ve made the wrong call now that ML and AI have become serious organizational priorities. The question is always framed the same way: which platform is going to win?
That’s the wrong question…and the cost of asking it is higher than most organizations realize.
These platforms aren’t two answers to the same question. They’re answers to different questions, optimized for different workloads, different users, and different moments in a data organization’s maturity. The organizations getting the most out of this landscape aren’t the ones who picked the right side. They’re the ones who stopped treating it as a competition and started treating it as an architecture problem.
What Each Platform Is Built For
Microsoft Fabric is a SaaS analytics platform with Power BI at its center. It sits on top of OneLake – a single, multi-cloud data lake shared by all workloads – and is designed to feel like a unified product rather than a collection of services. Data pipelines, Spark notebooks, a SQL warehouse, real-time intelligence, and Power BI semantic models all live in the same tenant and draw from the same pool of compute. You purchase a capacity SKU; workloads share that bucket. It’s a platform built for simplicity, predictability, and deep integration with the Microsoft ecosystem.
Databricks is an engineering-first platform built for teams that want to get close to the metal. Its Spark engine, with Photon acceleration, is best-in-class. Its Unity Catalog governance layer is the most capable open lake governance tool available. Its ML/AI toolchain (MLflow, Model Serving, Vector Search, Agent Bricks) is years ahead of most competitors. It runs on Azure, AWS, and GCP, and it’s built for organizations that treat data as a serious engineering discipline and are willing to invest in operating it accordingly.
These platforms aren’t two answers to the same question. They’re answers to different questions, which is exactly why the head-to-head framing so often leads organizations in the wrong direction.
Where Microsoft Fabric Genuinely Wins
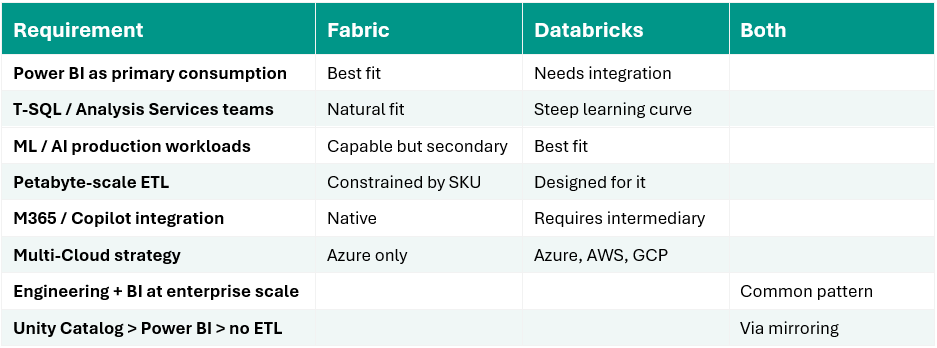
- BI is your dominant workload. If Power BI is how your business consumes data – dashboards, reports, executive scorecards – Fabric is the platform purpose-built for that world. With 35 million Power BI users globally, the ecosystem is unmatched. And with Direct Lake on OneLake now generally available, Power BI can query Delta files directly in the data lake at import-model speed, without scheduled refreshes and without copying data. For a BI-centric organization, this is the differentiating feature.
- Your team speaks T-SQL. Fabric’s Warehouse runs a real MPP T-SQL engine, and the platform feels familiar to anyone who’s worked in SQL Server, Azure Synapse, or SSAS. If your analysts and engineers are primarily SQL practitioners, the Spark-and-Python paradigm of Databricks introduces real friction. Fabric removes it.
- You’re running M365 and Purview. Organizations on M365 E5 with Microsoft Purview for governance will find that Fabric is the natural extension of that investment. Governance policies carry from Purview into Fabric. Data agents built on Fabric ground your M365 Copilot experiences directly in enterprise data and it’s the shortest path to that capability that currently exists.
- Predictable cost matters. Fabric’s capacity-based pricing means you buy a SKU and know your monthly bill. For organizations that want to avoid elastic compute surprise invoices, this predictability is a genuine advantage, even knowing that shared capacity means workloads compete for the same pool.
Where Databricks Genuinely Wins
- ML and AI are serious priorities. If your data science team is running production ML pipelines, fine-tuning models, or building AI agents over enterprise data, Databricks has the deepest and most mature tool chain available. MLflow, Model Serving, and Agent Bricks aren’t afterthoughts, they’re the reason a lot of organizations chose Databricks and never looked back.
- Your engineers are Python and Spark fluent. Databricks was built by the team that created Apache Spark, and it shows. The notebook environment, the Lakeflow declarative pipeline framework, and the cluster tuning flexibility are all designed for engineers who want a serious platform, not one that hides the plumbing. If your team has that skill profile, Databricks accelerates them. If they don’t, it creates complexity.
- You’re operating at a scale that strains Fabric’s ceilings. Fabric’s architecture is fundamentally a shared, vertically scaled SaaS capacity. It handles low-to-mid terabyte workloads well, but hits real architectural limits as data volumes grow: Power BI semantic models are memory-bounded per SKU (an F64 gives you 25 GB per model), and Direct Lake has explicit row-count and file-count limits at each tier. Databricks scales horizontally – you add clusters, not bigger boxes – and is comfortable with multi-billion-row fact tables, 100+ TB datasets, and complex transformations that would exhaust a Fabric capacity.
- Multi-cloud or open platform is on your roadmap. Fabric is Azure-only. If you have meaningful workloads on AWS or GCP or need governance that survives when data is read by Snowflake, Trino, or custom applications, Unity Catalog’s credential vending, Iceberg REST Catalog support, and Delta Sharing are built for that world.
The “Better Together” Story – and Why It’s a Bigger Deal Than It Sounds
Here’s what the market is converging on, especially at the enterprise level: use Databricks for data engineering, use Fabric for data consumption. Not as a compromise, as an intentional architecture.
The model is straightforward: engineering teams build and maintain medallion pipelines in Databricks using their Spark skills and Unity Catalog for governance. Business users access the gold layer through Power BI in Fabric, with Direct Lake performance, M365 integration, and Copilot capability. Each platform does what it was designed to do. Neither is asked to be something it isn’t.
What makes this architecture practical, not just theoretically appealing, is a capability that became generally available in July 2025: Unity Catalog mirroring into OneLake.
In plain terms: Fabric can now mirror Databricks Unity Catalog tables directly into OneLake without copying data. What gets replicated is metadata – table definitions, schemas, catalog structure – not the underlying Delta files. When Power BI or a Fabric notebook reads a mirrored table, it reaches back to the Databricks ADLS storage and reads the same parquet files the engineering team wrote. No ETL pipeline. No data duplication. The engineering team’s work is immediately available to Power BI consumers.
For organizations that have been hand-building data movement pipelines between Databricks and a BI layer, the operational savings are substantial.
One security consideration to call out explicitly: Unity Catalog privileges do not carry over when you mirror into OneLake. The Fabric mirror needs to be treated as an independent analytics perimeter. You’re managing three separate policy surfaces – OneLake Security, workspace roles, and Power BI RLS – that don’t talk to each other. Script the governance bridge before go-live, not after.
Direct Lake on OneLake completes the picture. This Power BI storage mode queries Delta files directly in the lake, combining import-model speed with live data freshness. One important caveat: it performs at its best only when Delta files are written with vOrder optimization. If your Databricks pipelines aren’t producing vOrder-optimized files, Direct Lake will underperform expectations, worth verifying before you build a semantic model on top of a mirrored Unity Catalog.
One thing worth naming before you finalize any architecture: the format war everyone expected, Iceberg versus Delta, never happened the way it was supposed to. Both vendors now support both formats. Databricks ships managed Iceberg tables in Unity Catalog readable and writable by external engines via the Iceberg REST Catalog API. Microsoft ships automatic Iceberg-to-Delta translation and OneLake Table APIs that speak the same spec. The competition has moved up the stack to the catalog layer: which governance plane owns lineage, access control, and sharing. That’s a meaningfully different question than which table format wins, and it matters for how you think about the architecture seam between these two platforms. Part 2 picks up exactly there.
A Framework for Making the Call
If you’re a Chief Data Officer or data platform lead working through this decision, four questions cut through most of the noise:
- What does your technology landscape look like? Microsoft-centric organizations on M365, Entra ID, and Purview will extract more value from Fabric faster. Heterogeneous or multi-cloud shops lean toward Databricks.
- What is your data scale? Low-to-mid terabyte BI workloads favor Fabric. Multi-terabyte or petabyte-scale transformation workloads favor Databricks.
- What does your workload mix look like? BI-dominant with some ETL? Fabric likely leads. ML and data engineering-heavy with BI as a downstream output? Databricks likely leads. Both at scale? Plan for both.
- What skills do you have in-house today? This is the most underweighted factor in most evaluations. The right platform is the one your team can actually drive. A SQL-centric team on Databricks is a path to underutilization. A Python-heavy ML team on Fabric is the same problem in the other direction.
One honest caveat: “both” carries its own cost, two FinOps practices, two governance planes, and a skill split you have to staff for. For smaller organizations without that operational capacity, the right answer may still be one platform done well.
One pattern that works well for mid-market organizations: start with Fabric. It’s the lower-friction entry point. SaaS deployment, unified billing, no cluster management, fast path to Power BI value. As ML and engineering needs mature, Databricks layers in. Critically, those investments stay compatible: Fabric Spark notebooks share the same Python paradigm as Databricks, and Unity Catalog mirroring means engineering work in Databricks surfaces directly into the Power BI environment the business already relies on.
What to do Next
Both platforms are moving fast. Direct Lake on OneLake went GA in March 2026. Unity Catalog mirroring went GA in July 2025. Waiting for one of these platforms to “win” isn’t a strategy, the integration story between them is getting tighter, not looser.
The organizations getting the most out of this landscape are the ones who did the honest work first: mapped their workloads, inventoried their skills, and made deliberate choices about where each platform fits. The ones struggling are the ones who picked a platform and tried to retrofit their needs around it afterward.
This post has given you the map. What it hasn’t given you is what happens when you actually try to run it. Part 2 of this series, Stop Waiting for a Winner, opens with a 3 a.m. failure that turns out not to be a platform problem at all. It’s the story that makes the architecture seam real, and it surfaces the organizational question that’s been underneath this platform argument the entire time, the one no vendor slide has ever addressed.


