On April 27, 2026, GitHub announced that Copilot is moving to usage-based billing on June 1, 2026. Premium request units are out; GitHub AI Credits consumed by token are in. For organizations running agentic workflows, this isn’t a pricing footnote, it’s a structural shift in how AI costs compound. This FAQ can help you better prepare. For more details on how to move forward as an organization, read Proving Agentic ROI Without Losing Control of Costs.
Understanding the Change
What is GitHub changing on June 1, 2026?
GitHub is replacing its flat-rate premium request model with token-based billing called AI Credits. Instead of a fixed monthly allotment of premium requests, your organization gets a pool of credits, and each AI action draws from that pool based on the tokens it actually consumes.
Why is GitHub making this change?
Copilot has evolved dramatically from a simple autocomplete tool into a full agentic platform. A quick inline suggestion and a multi-hour autonomous coding sprint that analyses an entire codebase and generates multi-file pull requests cannot reasonably cost the same flat rate. Token-based billing lets cost track actual usage.
Are base plan prices changing?
No. Copilot Business remains $19 per user/month and Copilot Enterprise remains $39 per user/month. What changes is how value is consumed within those plans.
What are the new credit allocations?

GitHub is providing a promotional credit bump through August to give organizations a cushion while they calibrate to the new model.
How Credits Are Consumed
What does NOT consume credits?
Inline code completions in your local developer environment — the suggestions developers use hundreds of times a day — do not draw from credits at all.
What does consume credits?
Agentic features draw from the credit pool, including:
- Copilot coding agent (Cloud / agent mode)
- Copilot Spaces and Spark
- Third-party coding agents integrated with Copilot
- Premium model selections (e.g. Claude Opus 4.7, GPT-5.5 cost significantly more per token than default models)
- Copilot Code Review (uses both credits and GitHub Actions minutes)
Are credits used per user or shared?
Credits pool across your entire organization, not per user. Lighter users effectively offset heavier users. This changes how you should think about allocation. A single power user running intensive agentic workflows can drain the shared pool quickly if left ungoverned.
What happens when credits run out?
This is a critical change from the old model. Previously, Copilot would silently fall back to a cheaper model when limits were hit. That automatic fallback is gone. When your credit pool is exhausted:
- If additional usage is enabled: work continues at published per-credit rates — real incremental spend on top of your subscription.
- If additional usage is not configured: usage is blocked until the next billing cycle.
No More Silent Fallback – Organizations must configure admin policies before June 1. Without them, you risk either unexpected overage charges or developers being completely blocked mid-sprint.
Agentic Workflows & Cost Exposure
Why are agentic workflows especially exposed?
Under the old model, you were charged per request regardless of complexity. Now you are charged per token and agentic workflows are non-deterministic. Sub-agents can spin up in parallel, retry operations, and compound token usage in ways that are hard to predict from past behavior. A single heavy workflow can drain a shared pool in ways a single developer never would.
What does a real agentic workflow actually cost?
Based on real-world SDLC work: a feature touching five components consumed approximately 118 credits (~$1.18). If that feature delivered $400 of business value, the ROI is strong. At scale, spending $1,000 in credits might return $40,000 in delivered value, but only if you have the visibility and governance to ensure the credits are being spent productively.
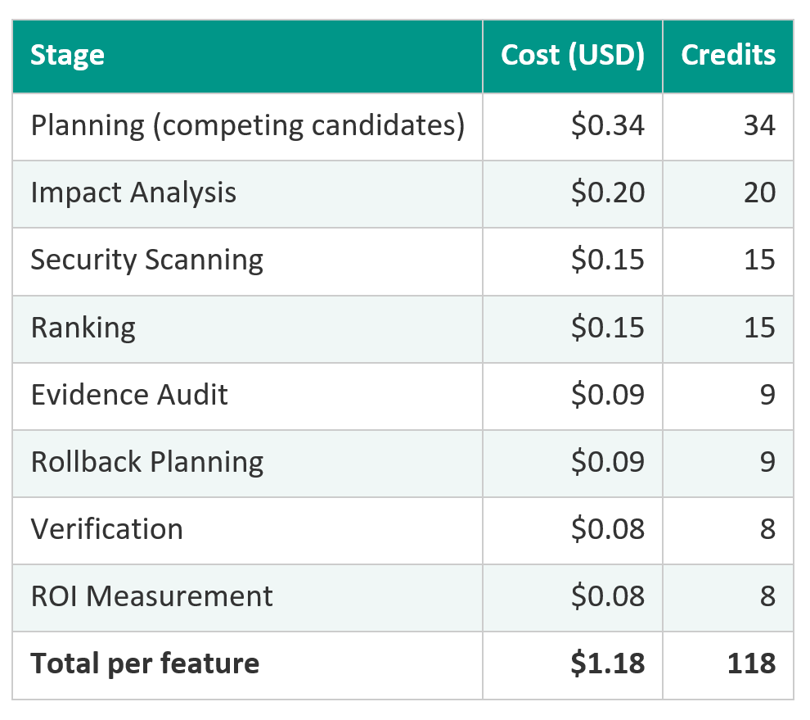
What are the biggest cost traps to watch for?
- Non-determinism: LLM costs do not follow linear patterns. Parallel sub-agents, retries, and recursive calls can multiply spend unexpectedly.
- Default to expensive models: Model routers default to the most capable (and most expensive) option without constraints. Match model choice to task complexity.
- The mid-pipeline hold trap: If you abandon an agentic task halfway through, you do not recover the tokens spent. In most cases, it is cheaper to complete the task on a lighter model than to abort and start over.
Measuring ROI in the New Model
How are most companies measuring AI ROI today, and what’s missing?
Most organizations rely on platform dashboards (acceptance rates, seat utilization, active users) and developer surveys (self-reported time savings). Both have value, but both share three critical gaps:
- Activity ≠ value. A 40% acceptance rate proves the tool is used. It says nothing about the dollar return on a specific initiative.
- Aggregation hides variation. A developer saving 4 hours on a complex feature gets averaged with one who lost 30 minutes chasing a hallucinated suggestion. The average looks fine; the reality is messy.
- No per-feature auditability. When finance asks for the return on a specific initiative, neither dashboards nor surveys can produce a traceable financial transaction.
What is per-feature economics and why does it matter now?
Per-feature economics means building a financial ledger for each feature: what it cost to plan, implement, and ship — including which agents and models were used — and what value it returned. This gives you:
- Concrete answers for CFO-level scrutiny, not just “we save 40% of the time”
- The ability to tune pipelines retroactively — make them cheaper or faster based on data
- A basis for expansion decisions grounded in measured returns, not assumptions
- Trend analysis that catches quality drift before it shows up in quarterly reviews
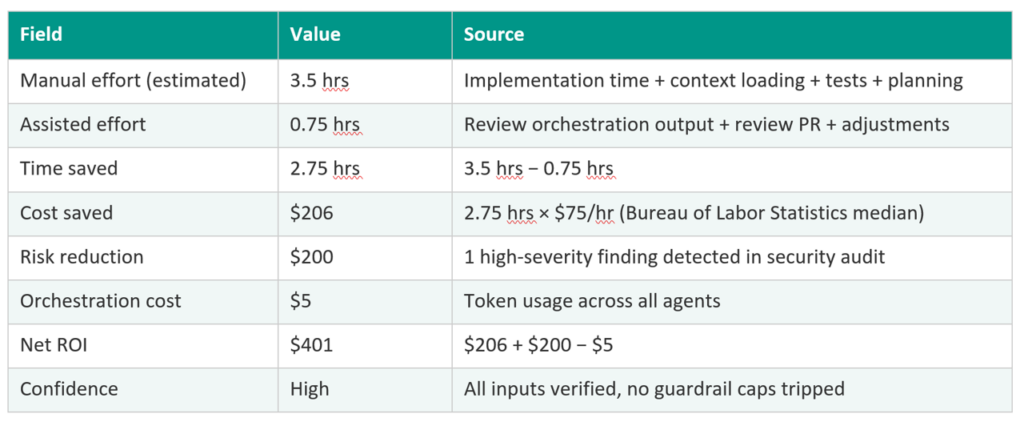
Why is keeping ROI numbers conservative so important?
When an AI system calculates its own ROI, there is an inherent incentive problem — numbers tend to inflate over time. Once stakeholders notice and trust erodes, it is very hard to recover. Three anti-inflation rules should be enforced architecturally, not just suggested:
- Cap time savings at 75%: No single calculation claims more than this ceiling, which is grounded in peer-reviewed research. If raw numbers exceed it, the system adjusts automatically.
- Zero value for hypothetical prevention: A clean security scan is a process benefit, not a financial event. Don’t claim dollars for vulnerabilities that weren’t found.
- Methodology travels with every number: Every rate has a research citation and documented assumption. A defensible $330 beats an impressive $800 that falls apart under scrutiny.
Governance & Admin Controls
What does proactive cost governance look like in practice?
Effective governance before June 1 includes:
- Pre-execution cost estimates — configure guardrails so you know what a workflow is likely to cost before it runs
- Progressive degradation — as the monthly pool depletes, automatically route to cheaper models rather than hitting a hard stop
- Spending caps by team, stakeholder, issue type, or cost center — decide in advance who can access more expensive model tiers
What admin controls does GitHub provide?
GitHub is shipping new admin controls specifically for this transition. You can set spending budgets at four levels in the admin console today:
- Enterprise level
- Organization level
- Cost center level
- Individual user level
Use GitHub’s Preview Bill Feature – In early May, GitHub is rolling out a preview bill feature. Turn it on now. It shows projected costs under the new model before the switch goes live June 1. This gives you a full month of real data, don’t wait for your first real invoice.
Leadership & Business Case
How does this infrastructure change conversations at the leadership level?
Per-feature economics and anti-inflation governance answer the three questions that consistently stall AI investment decisions:
- Where should we expand next? The ledger shows ROI broken down by complexity tier, risk level, and work type. Low-risk features might return $150 each; higher-risk ones closer to $500. That variation informs targeted expansion decisions.
- Is value holding or eroding? Trend analysis across the ledger catches quality drift before it appears in a quarterly review.
- What happens when we scale from 20 developers to 2,000? Pilot teams are cherry-picked for best fit; returns dilute as you expand. The ledger provides a grounded projection from measured data; leadership sees the diminishing return curve before committing budget.
The shift is from a faith-based conversation — “we believe AI is helping” — to a data-driven one where an auditor who was not involved in building the system can trace every ROI claim and rerun the formula.
Governance and measurement also stop being a separate function from delivery. With a per-feature ledger, cost governance becomes a byproduct of shipping — not a separate reporting exercise — and the conversation with finance moves from “how many people are adopting these tools” to “here is hard evidence of what we’re gaining.”
Your Action Checklist Before June 1
- Audit your agentic workflows. Know what they consume before the billing model changes, not after.
- Turn On GitHub’s preview bill when it rolls out in early May and actually read the numbers.
- Set Admin Budget Controls now at all four levels: enterprise, org, cost center, and user.
And beyond the immediate checklist, use this window to:
- Establish baseline cost estimates per feature type before pipelines run at scale
- Configure progressive degradation so a depleted pool results in cheaper work, not blocked work
- Begin building the per-feature ledger infrastructure now, so you have data when leadership asks
The Mindset Shift
Stop asking: “What does Copilot cost per seat?”
Start asking: “What does it cost per feature delivered, and what did the that feature return?”
Usage-based billing rewards organizations that plan ahead. The organizations that come out ahead on June 1 are not the ones who react to their first surprise invoice, they’re the ones who have already built the visibility and governance infrastructure to operate confidently.


