For many organizations pursuing AI initiatives, the road from pilot to production is lined with proof-of-concepts that never quite scale. The models work, the use case is strong, but momentum stalls just short of the finish line.
The reason is rarely technical. It’s organizational and more specifically, it’s the data.
While conversations around AI readiness often center on infrastructure, governance, or copilots, one capability is often overlooked: the data catalog. It doesn’t grab headlines, but it often determines whether an initiative remains stuck or moves forward.
A well-structured data catalog builds clarity, consistency, and trust across the enterprise. It helps teams align on language, reduce friction in data access, and strengthen confidence in AI outputs. More importantly, it brings technical and business users onto the same page.
This blog post looks at why data catalogs are essential to AI success, how they address common data challenges, and how organizations are putting them into practice.
The AI Readiness Gap No One Talks About
Enterprise AI often follows a predictable arc: successful pilots that fail to scale. Leaders may question model accuracy or readiness for production, but the root cause is often the underlying data.
Consider a team deploying a generative AI solution based on internal documentation. The prototype performs well—until business users begin testing it and uncover inconsistencies. The issue isn’t the model. It’s an outdated SOP or conflicting definitions baked into the data.
These breakdowns expose a common readiness gap: no shared understanding of what the data means, how it’s defined, or whether it can be trusted. According to Gartner, 60% of AI projects fail without an AI-ready data practice. Yet many organizations press ahead without addressing the fundamentals.
This is where a modern data catalog helps close the gap.
What a Data Catalog Actually Does
A data catalog is a centralized inventory of data assets—structured and unstructured—with the context needed to understand and use them effectively.
Modern catalogs capture metadata, definitions, lineage, classifications, and access rules to answer essential questions: What data exists? Where is it from? How is it defined? Can it be trusted?
Key capabilities include:
- Search and discovery: Find relevant data across systems quickly.
- Business glossary: Define shared terms and metrics across teams
- Data lineage: Visualize how data flows through systems and changes over time.
- Data quality insights: Identify issues such as duplicates or missing values.
- Access and compliance: Enforce role-based controls and sensitivity tags.
Platforms like Microsoft Purview and Databricks Unity Catalog exemplify this approach, offering scalable, integrated solutions that support both business users and technical teams.
The diagram below illustrates how Microsoft Purview brings together data mapping, classification, governance, and cataloging by linking metadata, lineage, glossary terms, and data products in one unified model. This architecture supports faster access, stronger governance, and greater trust in data across the organization.
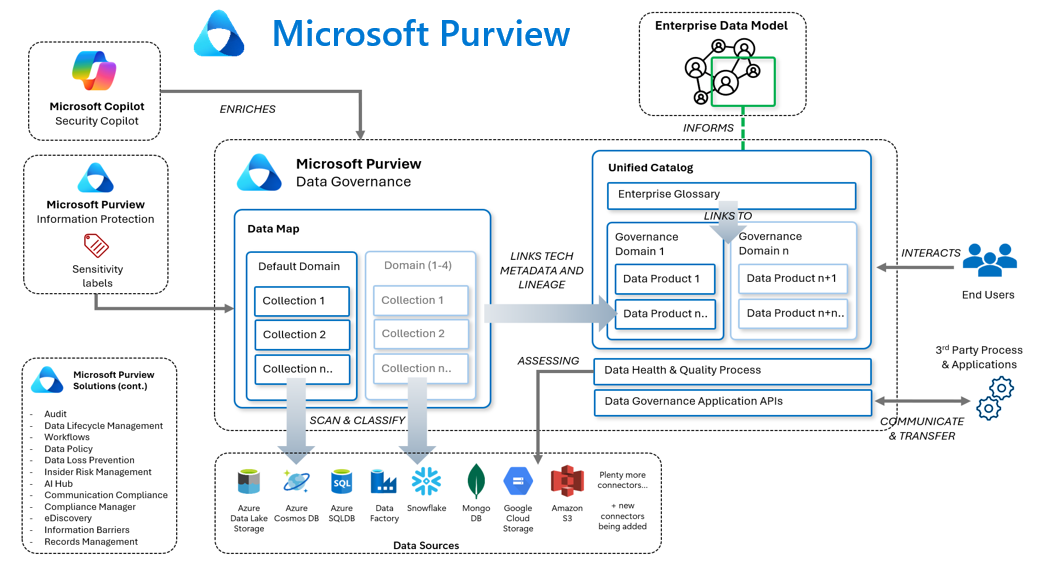
Why Data Catalogs Matter for AI
AI projects rely on well-understood, high-quality data. Without it, even the best models produce unreliable results and confidence in AI deteriorates quickly.
A catalog plays a central role in enabling AI readiness:
- Faster use case development: Teams find and understand data faster.
- Fewer definition disputes: A shared glossary prevents misalignment.
- Improved trust: Visibility into data quality and origin builds confidence.
- Stronger training datasets: Catalogs surface usable, high-quality data.
- Enterprise enablement: Non-technical users can engage more effectively with AI systems.
A common example: a business user flags an error in a generative AI output. The issue appears to be the model, but closer review reveals that the data was the problem. Outdated documentation or inconsistent terminology are frequent culprits.
Organizations with mature catalogs avoid these roadblocks. They create a shared understanding between data producers and consumers, making AI easier to deploy and scale.
Real World Example that Highlights the Power of Shared Language
After a series of mergers, our customer, a nationally distributed brewery company, faced challenges with inconsistent terminology across business units. The term “warehouse” meant different things in different systems, referring to physical locations, inventory zones, or distribution hubs depending on the source.
This lack of shared definitions created friction in performance reporting and made it difficult to align data across the organization.
To address the issue, the company implemented Microsoft Purview’s Unified Catalog and business glossary. Working with stakeholders, they standardized key terms and metrics to create a consistent reference point for both business users and report developers.
This alignment reduced confusion, streamlined reporting, and provided a stronger foundation for future AI and analytics initiatives.
Ready to assess your current state?
Lantern helps enterprise teams evaluate their data landscape, identify blockers, and take practical steps to improve AI readiness. From workshops to implementation support, we work with you to create a data environment that supports long-term AI value.
Sustaining the Catalog Through Business Ownership
Launching a catalog is a starting point. Keeping it accurate and relevant requires ongoing effort from the people closest to the data.
That responsibility can’t sit solely with IT. Business users, stewards, and subject matter experts must be involved in maintaining and evolving the catalog.
Best practices for shared ownership:
- Executive sponsorship: Leadership should prioritize catalog contributions as part of data strategy.
- Clear roles: Define who owns glossary terms, metadata reviews, and validation.
- Accessible tools: Use intuitive platforms with guided workflows and search.
- Value visibility: Demonstrate how the catalog improves reporting and accelerates AI delivery.
- Recognition: Acknowledge contributions to encourage engagement.
Data governance programs often begin as additional duties layered onto existing roles. With clear value and leadership support, they can become a consistent part of day-to-day operations.
How to Build Trust in Reports Created by Citizen Developers
As citizen development grows, so does the need for a framework to manage it. Business users build reports quickly, but not always consistently.
Without oversight, multiple versions of the truth can emerge. A data catalog helps by creating a structure for validation without slowing teams down.
Here are a few ways to manage report quality at scale:
- Certification workflows: Review and tag critical reports to confirm their accuracy.
- Metadata tagging: Label reports as “certified,” “draft,” or “personal” for clarity.
- Lineage transparency: Show where the data comes from and how it was transformed.
- Promote trusted content: Surface certified reports and datasets inside BI tools.
- Monitor usage: Track adoption of uncertified content and review when needed.
This structure helps organizations balance agility with governance and enables innovation that doesn’t sacrifice trust.
Additional Benefits for Governance, Quality and Compliance
Beyond AI enablement, a catalog delivers critical value in governance and data quality. These capabilities become even more important as AI and analytics move into regulated and enterprise-wide environments.
Benefits include:
- Defined ownership: Assign stewards and track responsibilities.
- Lineage tracking: Understand data dependencies for audits or root cause analysis.
- Compliance support: Identify and classify sensitive data.
- Data quality monitoring: Use scorecards to detect and address issues.
- Centralized visibility: Maintain a single view across hybrid or multi-cloud environments.
Strong governance supports responsible AI. A data catalog helps operationalize these practices and keeps them actionable.
Want to see what stalls AI initiatives and how to move past them?
In our AI Momentum webinar, we explore the biggest data challenges holding teams back from scaling AI. From poor data quality to siloed knowledge, learn what it takes to move from POC to production.
Conclusion
AI success depends on trust in the data behind it. A modern catalog strengthens trust by improving discoverability, transparency, and alignment across teams.
It’s not simply a documentation tool. It’s an enabler of speed, scale, and confidence, especially in complex environments where definitions vary, and data lives in many places.
Organizations that prioritize cataloging are better positioned to accelerate insights, reduce rework, and deliver value from their AI investments. For those just getting started, a focused use case or pilot can build early momentum and unlock long-term gains.


