Enterprise interest in AI has never been higher, but enthusiasm doesn’t always translate to outcomes. For many organizations, promising pilots lose momentum well before reaching production and it’s rarely because of model performance.
In our recent AI Momentum webinar, 72% of respondents said they “frequently chase down data” before they can begin building or validating AI solutions. That lost time isn’t just frustrating; it’s a clear signal of deeper structural problems.
The root cause? Misaligned systems, inconsistent definitions, poor data quality, and inaccessible knowledge.
According to Gartner, 60% of AI projects fail without an AI-ready data foundation. With as much as 90% of organizational knowledge locked in unstructured formats, even the most advanced models can’t perform without the right inputs.
These barriers aren’t new, but they’ve become more visible as enterprises shift from experimentation to scale. In this edition, we discuss the four most common data challenges slowing AI progress and what forward-looking teams are doing to overcome them.

1. Data Silos: When Critical Information Lives in Isolation
The Challenge: Disconnected data systems remain one of the most persistent and expensive obstacles to enterprise AI. When critical data is scattered across applications, departments, and cloud environments, AI efforts stall before they start. Teams often struggle with both locating relevant data and knowing what data exists in the first place.
Gartner surveys show that nearly 40% of organizations cite lack of data access as a top barrier to AI implementation. The core issue is data being locked away in different systems, departments, or formats, making it inaccessible when needed most.
Real-World Impact: One of our clients, Unifi Aviation, was able to anticipate safety risks using predictive and prescriptive analytics. They wanted to predict when safety incidents were more likely to occur across their 200+ airport locations serving nearly a million flights annually.
The key to their success? They had already invested in a centralized data platform that could combine flight data, weather data, personnel data, and shift data by location and station.
This unified approach enabled their AI models to identify patterns that would have been impossible to detect when data lived in separate systems. By connecting these previously siloed datasets, they achieved remarkable outcomes: after initial implementation stopped the year-over-year increase in incidents, they’re now seeing a 20% reduction in safety incidents. This is a real human impact that goes beyond operational metrics.
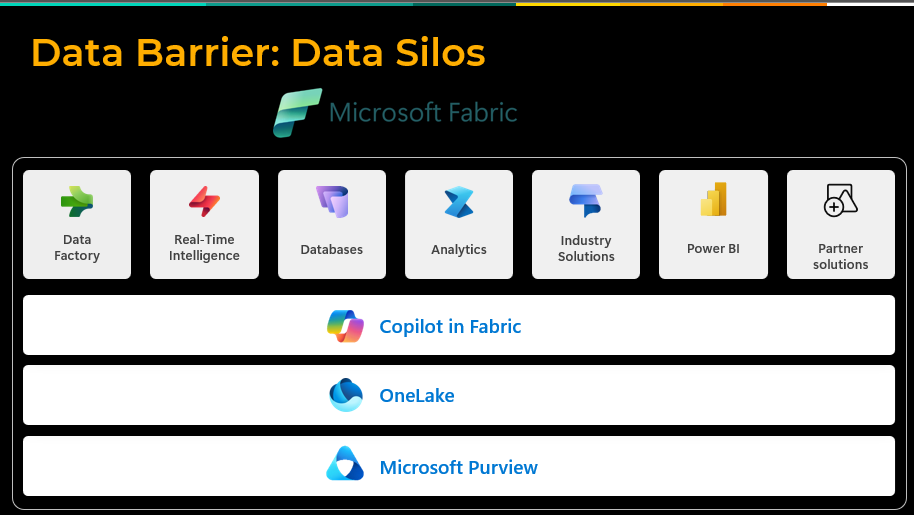
The Solution: Modern AI strategies don’t start with the model; they start with a connected data foundation. Platforms like Microsoft Fabric enable a unified, lake-centric architecture that improves discoverability, accelerates modeling, and reduces dependency on brittle integrations.
2. Data Catalog Confusion: When Definitions Derail Delivery
The Challenge: Even when organizations have access to the right data, alignment breaks down when teams can’t agree on what that data means. This challenge often emerges mid-project where one team defines “customer churn” based on inactivity, while another uses support ticket volume. The result? Time spent reconciling definitions rather than moving the project forward.
Real-World Impact: We worked with a nationally distributed brewery facing this exact challenge after several mergers and acquisitions. Different warehouses (the physical ones, not data warehouses) were using different terminology from their previous corporate entities. When trying to create performance reporting across warehouse operations, these inconsistent definitions made meaningful analysis impossible.
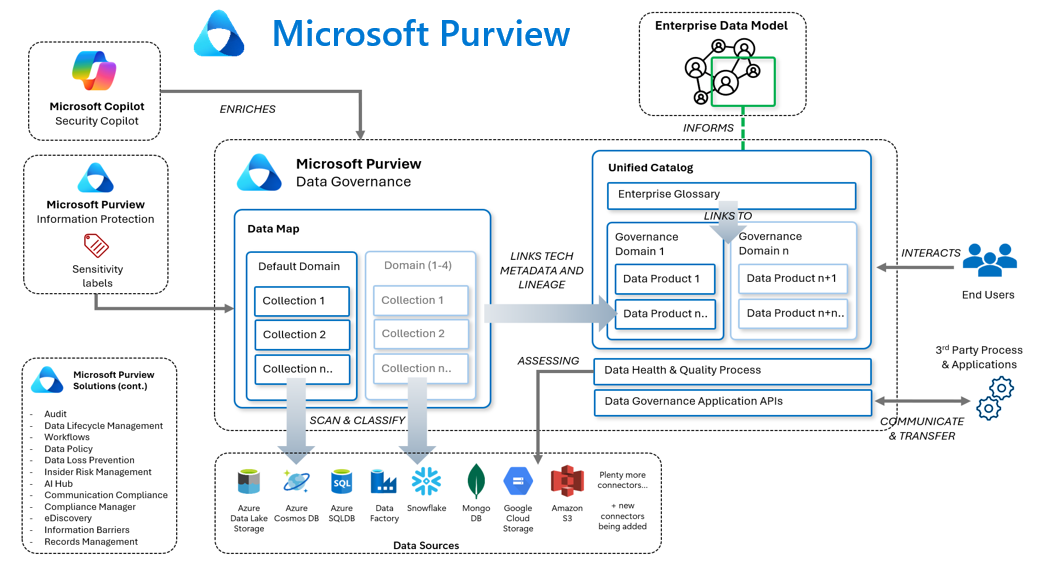
The Solution: Tools like Microsoft Purview help address this issue by centralizing business and technical definitions in a shared data catalog. By leveraging Purview’s Unified catalog, we established a common glossary and metric definitions that both business users and report developers could rely on. With clear understanding of what data represents, teams execute faster and with more confidence.
3. Data Quality Issues: When Trust in the Data Breaks Down
The Challenge: Low-quality data is one of the most common reasons AI outputs are questioned or dismissed. Duplicate records, outdated fields, and misclassified information all contribute to uncertainty, especially when decisions depend on accuracy.
This challenge is particularly visible in regulated sectors like healthcare or insurance, where small inconsistencies can lead to compliance risks or operational delays. Often, when an AI model produces an unexpected result, teams assume the model is incorrect when the real issue is upstream in the data.
The Reality Check: According to Gartner, through 2026, 30% of generative AI projects will be abandoned after the POC due to poor data quality. AI often surfaces problems that have been hidden in manual processes. If data quality hasn’t been addressed early, these gaps become more visible and harder to manage once automation is introduced.
The Solution: Data quality is more than cleanliness, it encompasses accuracy, completeness, consistency, timeliness, uniqueness, and conformity to organizational standards. Organizations that prioritize data integrity from the start are more likely to build AI solutions that are consistent, explainable, and trusted across the business.
Tools like Microsoft Purview provide data quality scorecards, health report dashboards, and rules-based scanning engines that can proactively monitor data pipelines and detect quality issues before they impact AI outcomes.
4. Unstructured Knowledge: Content That Can't Be Accessed or Used
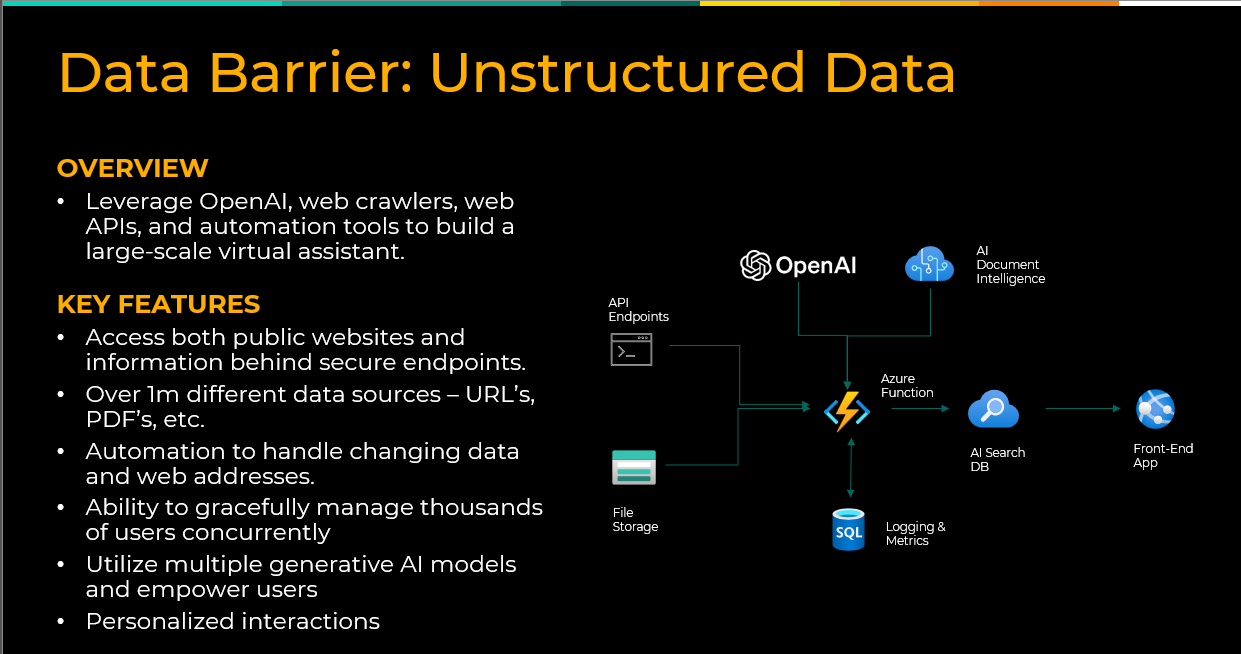
The Challenge: Across industries, most enterprise knowledge is buried in PDFs, emails, chat logs, slide decks, and internal documents. While structured data may fuel reporting and dashboards, unstructured content holds the operational knowledge that many AI use cases depend on.
Real-World Scale: We worked with a top academic medical school and research university to transform dark, unstructured data into searchable knowledge. The challenge was enormous – over one million documents across SharePoint, OneDrive, websites, textbooks, and research materials. Researchers and clinicians needed to quickly locate relevant information without knowing exactly where or how it was stored. Within a year, we scaled from a few hundred users to 4,000 active users, ingesting over a million endpoints.
The key insight? When you enable self-service AI insights for the experts who know the information best—clinicians, researchers, subject matter experts—utilization takes off dramatically.
The Solution: Solutions like Microsoft Fabric and Azure AI Search are helping organizations make unstructured knowledge discoverable and usable through RAG (Retrieval Augmented Generation) applications. These solutions allow users to bring their own data and have conversations with unstructured content, whether the goal is enabling copilots, powering internal search, or unlocking institutional memory.
The Governance Foundation: Right Sizing Your Approach
Here’s the inconvenient truth: most enterprises don’t have pristine data governance and that’s okay. You don’t need a perfectly buttoned-up data policy to start AI work. But what you do need is a plan to avoid governance chaos once the proof-of-concepts become production.
Think of it like moving into a new house: you don’t need every shelf labeled on day one, but you’ll regret not having a system before the boxes start piling up.
Start Focused: Begin with a critical business process and build proper data governance into that specific use case. Don’t try to boil the ocean—focus on critical processes first and evolve your governance practices from there.
Executive Sponsorship is Critical: Data governance is fundamentally about people and process, with technology as the enabler. It requires executive sponsorship and understanding that governance is as critical as data security, especially with evolving AI regulations.
Collaborative Ownership: AI demands much better collaboration between business and IT than traditional technology projects. By involving the right people from the beginning and having their roles evolve throughout the project, you build ownership and get better results.
What You Can Do Next
If your AI efforts are slowing down, it may be time to revisit the foundation. These barriers—siloed systems, unclear definitions, data quality gaps, and inaccessible knowledge—can all be addressed with the right approach.
The organizations seeing real AI success aren’t waiting for perfect data conditions. They’re taking a pragmatic, focused approach: identifying high value use cases, building governance into those specific business cases, and evolving their data practices as they scale.
Ready to assess your current state? Contact our team, we help enterprise teams evaluate their data landscape, identify blockers, and take practical steps to improve AI readiness. From workshops to implementation support, we work with you to create a data environment that supports long-term AI value.