Microsoft made waves in the market this week with the announcement of Microsoft Fabric. It’s hard to exaggerate just how huge this is so I just want to focus on the single feature I’m most excited about: Direct Lake.
Direct Lake in a Typical Data Warehouse Architecture
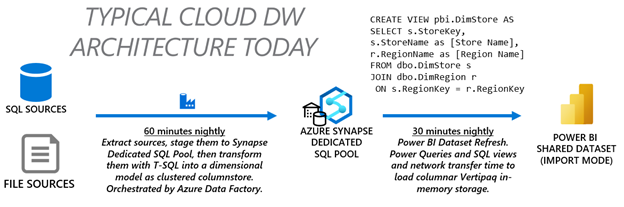
To set the stage for why Direct Lake is so exciting, here’s an illustration of a common approach to analytics today. Let’s say you spend 60 minutes incrementally loading your enterprise data warehouse nightly and another 30 minutes refreshing the Power BI dataset.
Here’s what the architecture could look like in Fabric:
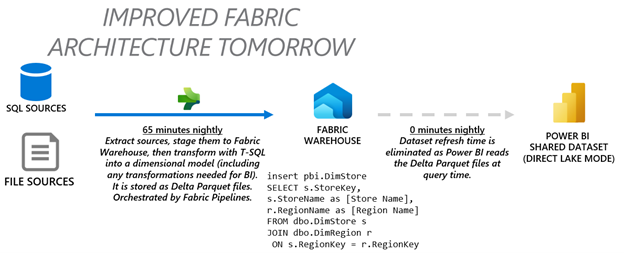
In loading a Fabric warehouse, we are actually writing to OneLake in the Delta Parquet (Delta Lake) file format. Then Power BI Direct Lake mode puts Power BI directly on top of the Delta Parquet files. Dataset refresh time is completely eliminated which reduces the impact on your Power BI premium capacity and reduces latency for displaying fresh data in your reports. When you render a report, the columns are loaded on-demand into memory and reports perform blazing fast like an Import model.
This is groundbreaking stuff that nobody else in the market has!
One thing the diagram calls out is that is that any Power Query transformations or SQL views will need to be materialized as tables. Ideally, the data integration team and the BI team will coordinate closely to pull this off.
However, Fabric is extremely flexible in how work is organized. I can imagine large teams may want more separation of duties. For example, the data integration teams load a warehouse in a DW workspace, the BI team creates a separate BI workspace with OneLake shortcuts to the tables from the DW workspace, then the BI team builds additional data integration steps which materialize the transformations they need for BI.
Direct Lake in a Typical Data Lake Architecture
What if you have typical data lake architecture like the following?
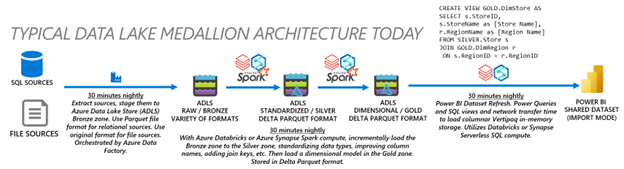
Direct Lake integrates extremely well:

By standardizing on the open Delta format and standardizing on OneLake which can speak Azure Data Lake Storage Gen2 protocols, you can continue to load your data lake with Azure Databricks compute if you wish. Or you can move to Spark compute in Fabric.
One interesting innovation is that Microsoft has brought some intellectual property from import model Vertipaq compression and applied it to Parquet files. They call it v-ordering and it improves compression by sequencing the data. The Parquet files are still 100% Delta Lake compatible, but it can improve the performance of Direct Lake.
It’s still early days for Direct Lake, but I’m incredibly excited to work with my clients to think through how Fabric and Direct Lake can improve time-to-value and streamline their approach to data analytics.
I’ve Been Asking for This!
To explain just how delighted I am in this feature and how much Microsoft exceeded even my wildest imagination about what was possible, let me turn back the clock a couple of years. Power BI is growing like crazy and is wildly successful by any measure. So what happens when you take the leaders over Power BI like Arun Ulag and Amir Netz and give them ownership of other platforms like Azure Synapse?
That’s exactly what happened in 2021 and when I heard about this, I immediately sent an email to Amir sharing an idea on how I thought Synapse and Power BI could improve. What they delivered was so much more comprehensive and brilliant than any of my pale ideas, but I think it shows just how delighted I am in Direct Lake as a perfect solution to something I’ve wanted for years.



